Organizations need to deliberately create data
Why we need to stop thinking of data as oil


The metaphor of oil for data is incredibly pervasive. The metaphor infuses a lot of our core data vocabulary - you see it in common terms like “data extraction”, “data mining” and “data pipelines”.
The impact of the metaphor becomes particularly clear when we look at how data scientists work. In most organizations today, when a data scientist is charged with developing a new model to predict something, the first thing she will do is list a number of features she thinks are likely to be predictive. The second thing she will do is to look at whether there are data sources in the organization that she can extract and refine suitable data from, to engineer those features. In many cases she will conclude that many of the desired features she would like cannot be engineered because the required source data is not available. Her world is bounded by the data available at their organization - by the “wells” of data available to be extracted.
The impact of the metaphor is also clear if we look at any coverage of the Modern Data Stack. On the left of any diagram of the Modern Data Stack are the “data sources” - listed in much the same way oil firms create geological surveys of the world to identify the different areas with oil, suitable for extraction. “This is the (bounded) universe of places you can find data to replicate into your cloud data warehouse!”
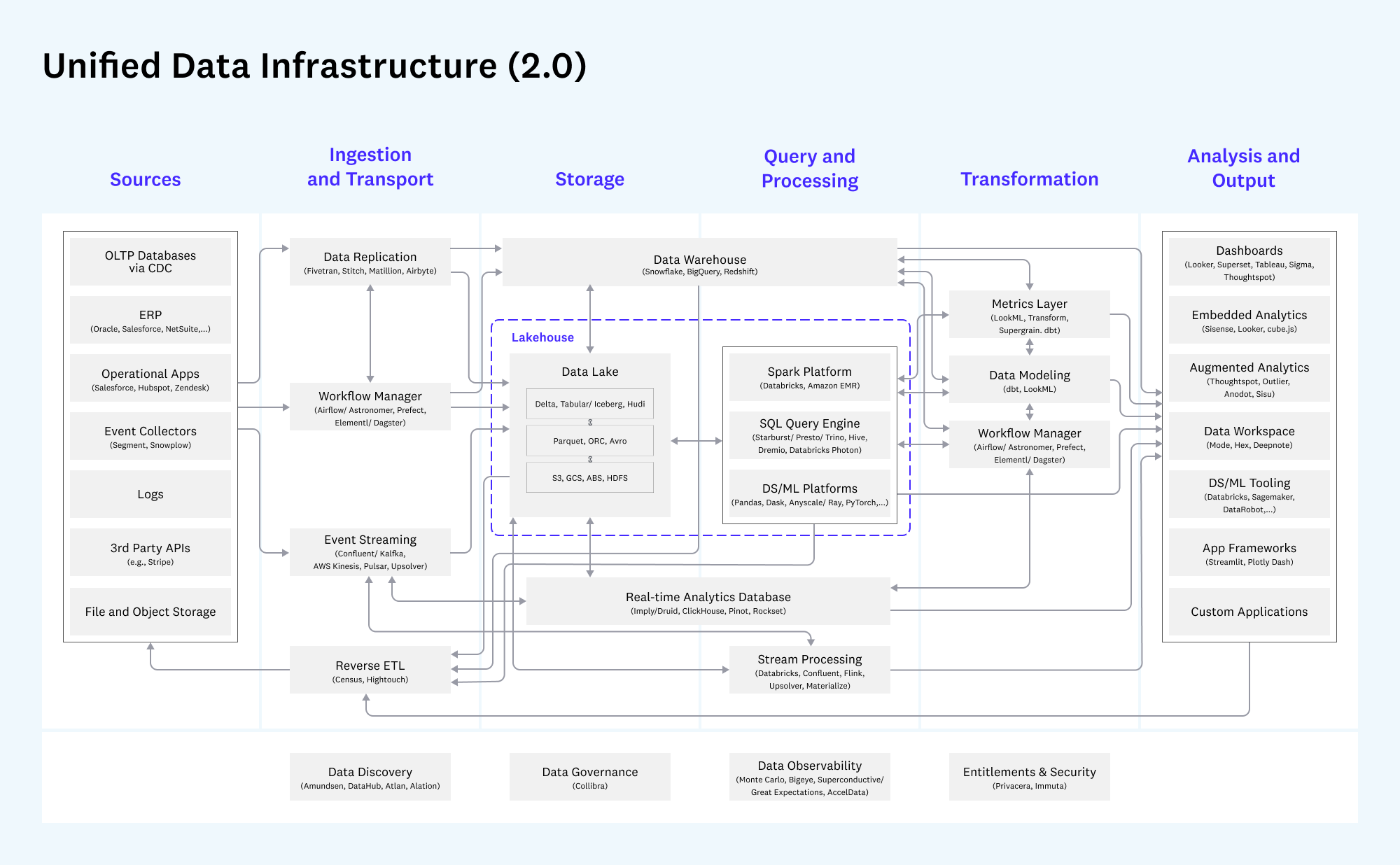
Diagram taken from a16z blog post Emerging Architectures for Modern Data Infrastructure, https://future.com/emerging-architectures-modern-data-infrastructure/
In both cases, the assumption is that the data scientists developing the algorithms and models, or the users of the modern data stack being assembled, have
a limited number of data sources that they can tap, and
investment will need to be made in extracting, replicating and transforming the data to get it into a format from which it is possible to drive value from.
By implication, there is no data outside of those identified sources.
These assumptions are fundamentally wrong. Organizations can deliberately create the data that data scientists and other data consumers need, data that today those organizations simply do not have. More than that, organizations should deliberately create the data that they need: as Peter Norvig observed many years ago - “more data beats clever algorithms, and better data beats more data”: so it makes sense to spend at least as much time creating better data as developing better algorithms. In this post, I’m going to try and persuade you that organizations should invest in creating better data - and that investment can directly drive value and competitive advantage.
The limits of data extraction
The tooling for working with extracted data, and turning it into something that can be used to drive value, has never been better. The ecosystem that has grown up around the Modern Data Stack means that it has never been easier to build data pipelines that extract data from multiple sources (using tools like Fivetran, Airbyte and Meltano), transform it (using tools like dbt and Matillion) into a structure optimized for analytics and machine learning and deliver it into different analytics and activation tooling. Given there is so much value to unlock by adopting these tools and approaches, maybe it’s awkward to highlight that there are fundamental limitations to feeding this ecosystem of powerful tooling for driving value from data with data that is fundamentally limited. Unfortunately, we need to, because there are significant, fundamental challenges to working with extracted data, even with all that tooling available.
Data Scope and Granularity
Sometimes you want to engineer a feature or report on some behavior for which no data is available. Source data systems are finite: they have a certain amount of data with a certain associated scope. When a data scientist abandons developing a particular feature because the data is lacking, it is often down to the scope of the source data available.
Data quality
Data quality has become a bigger and bigger topic in data in general, as organizations start using data in more and more sophisticated ways, because more sophisticated data processing techniques require higher quality data. There has been an explosion of great tools to help companies build assurance in the quality of their data, solutions that include Monte Carlo, Datafold and Great Expectations. These tools provide structured approaches to check the properties of source data to ensure they are as expected, and build assurance that any subsequent processing steps don’t introduce new data quality issues. (This is really where these tools shine.) But by definition, there’s nothing these solutions can do to fix the quality of the source data - that is a given - and at best they can only flag likely issues. Data isn’t like oil - you don’t improve the quality of data by removing impurities from it - good quality data is created by ensuring that your process for creating the data is robust. For example, if you have a data set that describes the temperature of part of an engine over time, that data set is only as good as the equipment that was used to record the temperature and how well that equipment was used to generate the data set. If after the fact you find that some of the readings suggest the data isn’t accurate (e.g. they are suspiciously high), no amount of “cleaning” the data is going to resolve the issue that the data probably can’t be relied on. The quality of any derived data set will always be limited by the quality of the data at source. As the old saying goes, “garbage in, garbage out”… (Or as the English say, “you can’t polish a turd”, although it has not stopped lots of people in data spending lots of time scrubbing.)
Data Interpretability and Semantics
As organizations have started to use data to power more and more different applications and products, there has been an increasing understanding that data needs to be well understood and documented: it needs to be straightforward for a data consumer to understand what each row and column of data means. This has also led to another explosion of great technologies including semantic layers like AtScale, and Data Catalogs like Atlan, DataHub and Amundsen.
These solutions generally look to solve the problem of data meaning in the presentation layer: at the point that the data is made available to the rest of the organization. Meaning is effectively applied to the data (generally in the form of metadata) at the end of the processing. This means there are limits to how well understood the data delivered can be, because there is no solution to manage the meaning of the “source data” on which that presentation layer has been built. Instead, the metadata that captures the meaning has to be assembled by knowledgeable practitioners, generally after a long and tedious manual process unpicking the process for how the data was generated. Some of them work back from the presentation to provide visibility of the pipelines and processes that feed that presentation layer. Some of them use ML and social annotation features to support the process of curating the metadata and keeping it up to date. But none of them are able to work all the way back to the source systems where the data was originally extracted, where the data, and therefore the meaning originates.
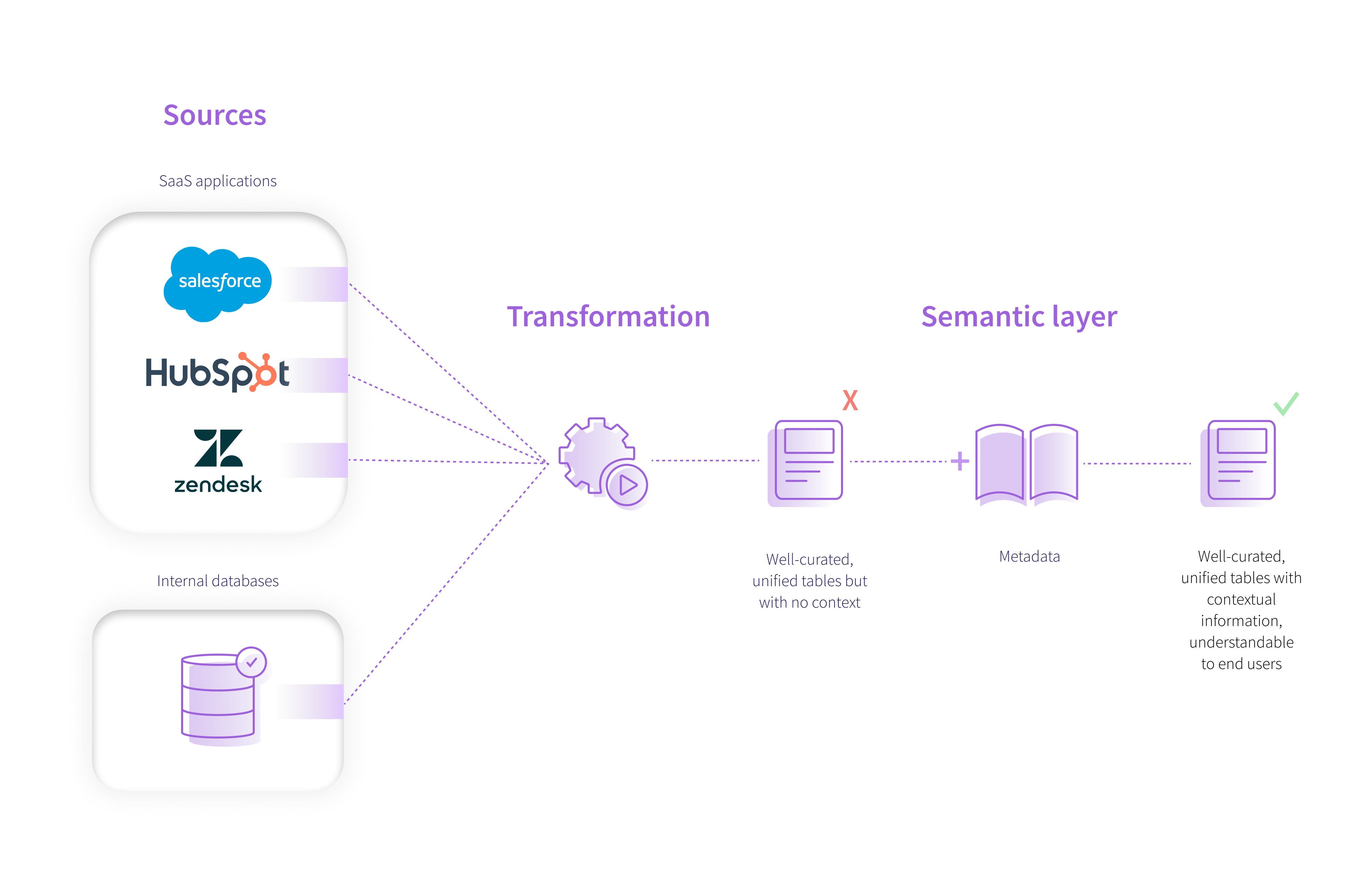
When people in an organization look at data sources for potential data to extract, they typically find two types source:
SaaS applications like Salesforce. The data in these systems is typically extracted via APIs.
Databases within the organization. These have typically been built to support the applications that have been built by the organization themselves to support them doing business.
In both cases, each data set has been created to support an application - in the first case an application developed by a 3rd party vendor, and in the second, an internally developed application.
Now, to understand what that data actually means, we need to understand:
How the application works. (In the case of Salesforce - an understanding of the concepts of things like accounts, opportunities and contacts)
How the application is, and has been used by the organization in question
This is not straightforward. Anyone who has ever tried to work with the old format Adobe “hits tsv” knows how much Adobe and implementation specific information is required to wrangle long lists of sProps and eVars. (Thankfully the format of data created by Adobe AEP today is infinitely superior.) Anyone who has tried to work with Salesforce data knows how sensitive the extracted data is to the particular ways in which individual companies have applied concepts like leads and contacts. In the vast majority of companies this sort of knowledge is tribal knowledge - stuck in the head of a handful of internal experts. Any data product managers, engineers, scientists that want to do anything valuable with the data will have to mine those internal experts to do anything valuable with the data from those sources.
As a result, it is very hard to draw meaning from the data from those source systems. This is one reason why driving value from that data is so hard: one of the reasons why so much time and investment has to be made to deliver a well curated data catalog or semantic layer.
Data structure
The structure of data extracted from different sources system is never optimized for machine learning or advanced analytics. This should not be a surprise - the data is structured in a way that is optimized for the application that it has been created to support, not the predictive model the data scientist is looking to build.
This is the second reason why organizations have to invest so much time today in data preparation: they are building data platforms on top of source data systems that do not reflect the plethora of data applications the data platforms need to support: instead they reflect the set of SaaS tools and internal applications that have been built to meet a completely different set of needs the organization has had to date.
In order to make that data usable for machine learning or advanced analytics, an enormous amount of data processing is generally required.

Managing change
One of the biggest challenges with relying on data extraction is managing change. A source system can change at any point in time: because the data extracted is a bi-product, it is generally completely opaque to the people that manage the application that changes that they make could fundamentally break any downstream data pipelines and data applications that rely on the data: none of those dependencies are explicit. If you are lucky, the actual data pipeline will fail, and someone can spot and address the issue. (A lot of investment is often made in creating CICD tests to try and do just this.) But if not, then the meaning of the data could change, without any obvious way for the people curating the semantic layer, data catalog or downstream applications to identify and adapt to the change. Building applications on this data pipelines that are fed by these sources is literally like building houses on stilts: the foundation is totally unsuitable for the structure it is supposed to support.
https://www.flickr.com/photos/79505738@N03/44203546932
Data Creation is a real and attractive alternative for data extraction
Organizations can and should deliberately create data to power machine learning and advanced analytics use cases, rather than relying on data extraction. This means that when a data scientist decides that a particular feature is likely to be valuable for a model they are developing, they should look at how the organization can go and create that data, rather than limiting their search for features to those that can be readily delivered using existing data sources.
The good news is that increasingly, organizations are creating their own data. To give just two examples:
Retail bank creates data to reduce fraud
A set of data scientists at a bank hypothesized that how an individual fills in a credit card application might be predictive of how likely that individual was to be applying fraudulently: for example, a user who tries pasting multiple specific social security numbers into the application form sequentially is likely to be making a fraudulent application. Similarly, a user who completes an application very quickly might not be a human but a bot - suggesting suspicious activity.
This data can readily be created using open source technology like Snowplow (disclaimer: I am one of the founders of Snowplow) or alternatives. Indeed we have worked with a number of institutions to create data to enable features that are predictive of fraud, enabling those institutions to block fraudulent transactions and approve legitimate transactions faster. Behavioral data, describing what the individual submitting a transaction or credit application, has been found to be one of the most predictive indicators of fraud: incorporating this created data drives a step change in fraud detection performance. Yet this is a signal that many financial institutions ignore, because the data is not readily available to the data scientists: it needs to be created.
Insurance company creates data to measure exposure to flooding risk
Last year Europe saw widespread flooding. One of them realized that they did not have a way to accurately measure their exposure to flooding risk across their property portfolio. Although they had a list of addresses for all the properties that they insured, GPS coordinates for each property and accurate topographic maps covering Europe, it was not possible to tell how much damage would be done at different levels of flooding, because the perimeters of each property were unknown: instead only a single GPS coordinate given for each address, and sometimes this coordinate was not even within the perimeter of the property.
As a result, a data product manager assembled a team to solve this problem: their job was to create a data set that gave the perimeter of each property, so that the risk team could use that data to provide much better models for the impact of different levels of flooding on property damage across their portfolio. (By combining the perimeter data with the topographic data to figure out how much of each property would be submerged at different levels of rainfall.)
The data product manager and his team visited several hundred sites to directly measure the property perimeters, and then used that data to train and test a machine learning model that predicted those perimeters from satellite imagery. The resulting data made it possible for the risk team to drive a step change in modeling their exposure to flooding risk, and the insurance company is now exploring investing in developing many more data sets to drive improved risk modeling.
One of the most exciting applications for machine learning, in data, is actually as part of the Data Creation process. Whilst in data we typically think of machine learning as a powerful tool for driving insight and prediction from data, it can be a useful tool in building a predictive data set to start with. At Snowplow, we see more and more of our customers and open source users recording the predictions that they make as behavioral data (in this case the behavior of the machine learning application) alongside behavioral data that describes the individual people who’s behavior powered those predictions.
So if Data Creation is so much better than Data Extraction, why do so many organizations still rely on extraction for the vast majority of their data?
This is particularly surprising because as a whole, mankind is creating more data than ever.

Graph taken for Statista, https://www.statista.com/statistics/871513/worldwide-data-created/
It is just that by and large, data is being created by vendors of particular applications and products, rather than organizations looking to develop data platforms for their own internal uses. I think there are a couple of reasons for this:
The tooling for Creating Data is not good enough today. (I say this as the founder of a company trying to build better tools to create data.) For most data scientists that want to build a new data application and need to engineer a feature, it is easier to start with data that is already in the organization, however imperfect, than create that data from scratch. This is something that we are actively looking to change at Snowplow.
The “data is oil” metaphor is so pervasive in data that it simply does not occur to the vast majority of data practitioners. We have all been indoctrinated in the idea that data engineering starts with the data that an organization already has. To be fair, a huge amount of value has been unlocked by taking that data, bringing it together in a cloud data warehouse / lakehouse, and then building intelligence and activation on top of it. But so much more can be accomplished if organizations look beyond the data that they happen to have today, and start to deliberately create better data to power their data apps for tomorrow.
This is so accurate. It still boggles my mind that organizations often don't invest in data collection efforts and are just happy to use whatever data is made available to them by other organisations.
Everybody wants to build personalized experiences without the effort of understanding their audiences, it's so crazy!